Announcing the ARC White-Box Estimation Challenge
ARC has teamed up with AIcrowd to launch the ARC White-Box Estimation Challenge, a contest to improve upon our estimation algorithms for random MLPs. The warm-up round begins this week, and later rounds will have a total prize pool of at least $100,000.
We are very grateful to Sharada Mohanty, Sneha Nanavati, Dipam Chakraborty and everyone else at AIcrowd for working with us to host this contest, as well as to Paul Rosu for testing the contest and to Harshita Khera for operational support.
Introduction to the Challenge
Our challenge follows the same setup as our recent paper on wide random MLPs: we consider MLPs \(M_{\theta}:\mathbb R^n\to\mathbb R^n\) with weights \(\theta=\left(\mathbf W^{\left(1\right)},\ldots,\mathbf W^{\left(L+1\right)}\right)\in\mathbb R^{\left(L+1\right)\times n \times n}\), defined by
\[M_{\theta}\left(\mathbf x\right)=\mathbf W^{\left(L+1\right)}\phi\left(\mathbf W^{\left(L\right)}\ldots\phi\left(\mathbf W^{\left(2\right)}\phi\left(\mathbf W^{\left(1\right)}\mathbf x\right)\right)\ldots\right),\]
where the activation function \(\phi\) is \(\text{ReLU}\left(z\right):=\max\left(z,0\right)\), applied coordinatewise.
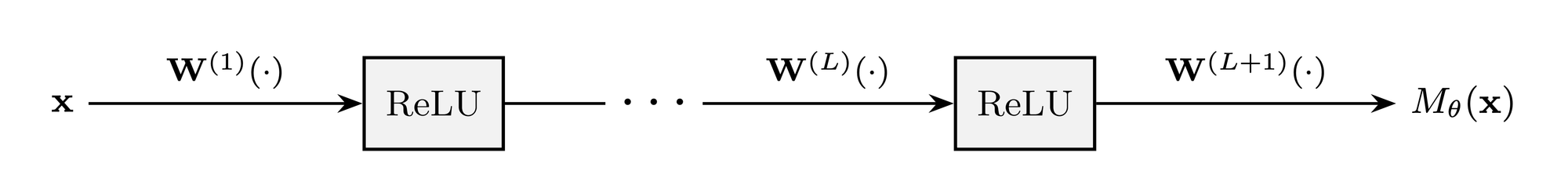
To begin with, we are fixing the width \(n=256\) and the number of hidden layers \(L=8\), but we expect to change this setup in future rounds.[1]
Contestants must design an algorithm that takes in a set of weights \(\theta\) and produces an estimate for the expected output
\[\mathbb E_{X\sim\mathcal N\left(0,\mathbf I_n\right)}\left[M_{\theta}\left(X\right)\right].\]
Algorithms will be evaluated on MLPs with randomly-sampled Gaussian weights. The goal is to achieve as low mean squared error as possible, subject to certain computational constraints.
We have devised a FLOP-counting scheme with AIcrowd to minimize any advantage from using heavily optimized numerical kernels, allowing participants to focus on higher-level algorithm design instead. This scheme may still have a few rough edges remaining, but we hope to round these out over the course of the warm-up round.
For further details, please see the challenge website.
Why run this contest?
In the long run, we would like to answer questions about highly intelligent AI systems such as, "Are there unusual situations in which the system would undermine human control?". Running the system on a huge number of different inputs may not be a reliable way to answer such questions, since a highly intelligent system may not fall for our "honey pots". This why we are interested in white-box approaches that leverage our access to the model's internals. Ultimately, of course, we should use whichever methods perform the best.
Unfortunately, designing highly performant white-box estimation methods for trained networks is challenging, even for tiny models. ARC's bet is that we can build up to this challenge by first producing performant white-box estimation methods for randomly-initialized networks, and then figuring out how those methods can be adapted with each step of training. However, even this first step remains incomplete. In our recent paper, we produced white-box methods that outperform black-box methods for MLPs with large width, but they break down as the depth grows, and we are very confident that our methods can be significantly improved.
By running this contest, we hope to spur others to discover such improvements. Even though "white-box" is in the name of the challenge, contestants are permitted to use any methods they choose, whether white-box or black-box: as stated above, we ultimately want the best-performing algorithm. However, we strongly expect the best possible algorithms for this problem to be "mechanistic" (i.e., to avoid black-box sampling entirely), mirroring our existing results in the large width setting.
Use of LLMs
We encourage contestants to use LLMs to whatever extent helps them improve their submissions the most. In later rounds, there will be two kinds of prize: one for the best-performing submission, and one for our favorite algorithmic contribution described in a technical report. Especially for the latter kind of prize, contestants may benefit from having a good understanding of any LLM-written code themselves, but the rules of the contest do not require this.
In fact, exploring LLM usage is another motivation for holding the contest. Thanks to how our research has developed, it now looks possible to make progress on some of our core problems by hill-climbing on well-defined metrics, which is exciting to us.[2] At the same time, the ability of LLMs to make considerable progress on such problems is improving rapidly, and we want to position ourselves to take full advantage of this. We are not sure whether we will be able to draw generalizable insights from strong submissions that are primarily LLM-written, but we think putting LLMs to work on the problem is a worthwhile experiment nonetheless.
As a word of caution, our FLOP-counting utility is definitely hackable in ways that would be very unambiguously hacking once pointed out, such as by modifying constants or counts held in memory. Contestants are responsible for ensuring that their submissions do not hack our FLOP-counting utility, regardless of whether or how they choose to use LLMs.
To all contestants: good luck!
Cross-postings for comments: LessWrong, Alignment Forum
The contest setup is actually slightly different in that it omits the final linear layer, but this makes essentially no difference. ↩︎
We have previously offered prizes for solutions to problems, but they have either been more pedagogical or less central to our agenda. ↩︎