Finding gliders in the game of life
ARC’s current approach to ELK is to point to latent structure within a model by searching for the “reason” for particular correlations in the model’s output. In this post we’ll walk through a very simple example of using this approach to identify gliders in the game of life.
We’ll use the game of life as our example instead of real physics because it’s much simpler, but everything in the post would apply just as well to identifying “strawberry” within a model of quantum field theory. More importantly, we’re talking about identifying latent structures in physics because it’s very conceptually straightforward, but I think the same ideas apply to identifying latent structure within messier AI systems.
Setting: sensors in the game of life
The game of life is a cellular automaton where an infinite grid of cells evolves over time according to simple rules. If you haven’t encountered it before, you can see the rules at wikipedia and learn more at conwaylife.com.
A glider is a particular pattern of cells. If this pattern occurs in empty space and we simulate 4 steps of the rules, we end up with the same pattern shifted one square to the right and one square down.

Let’s imagine some scientists observing the game of life via a finite set of sensors. Each sensor is located at a cell, and at each timestep the sensor reports whether its cell is empty (“dead”) or full (“alive”). For simplicity, we’ll imagine just two sensors A and B which lie on a diagonal 25 cells apart. So in any episode our scientists will observe two strings of bits, one from each sensor.
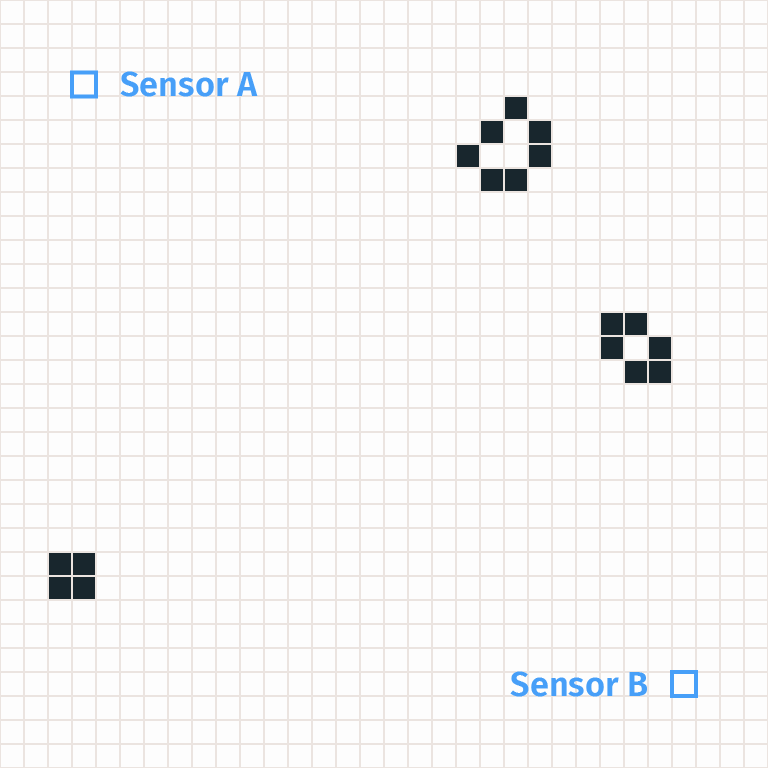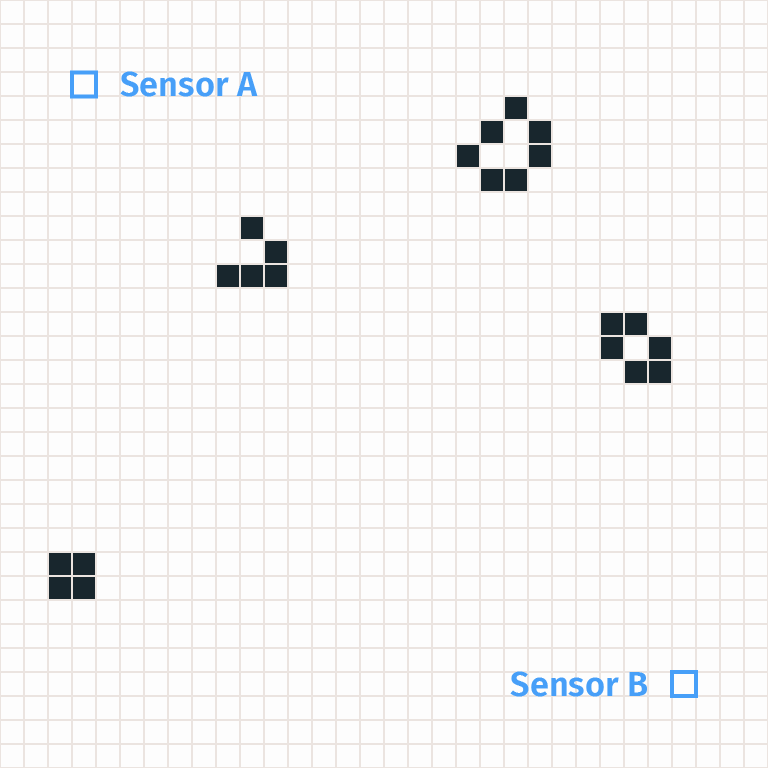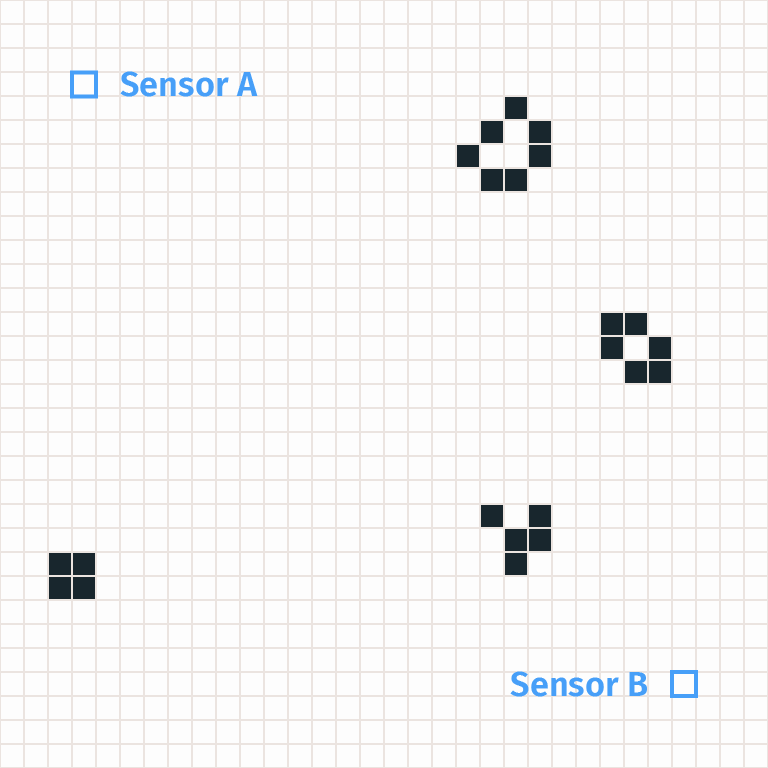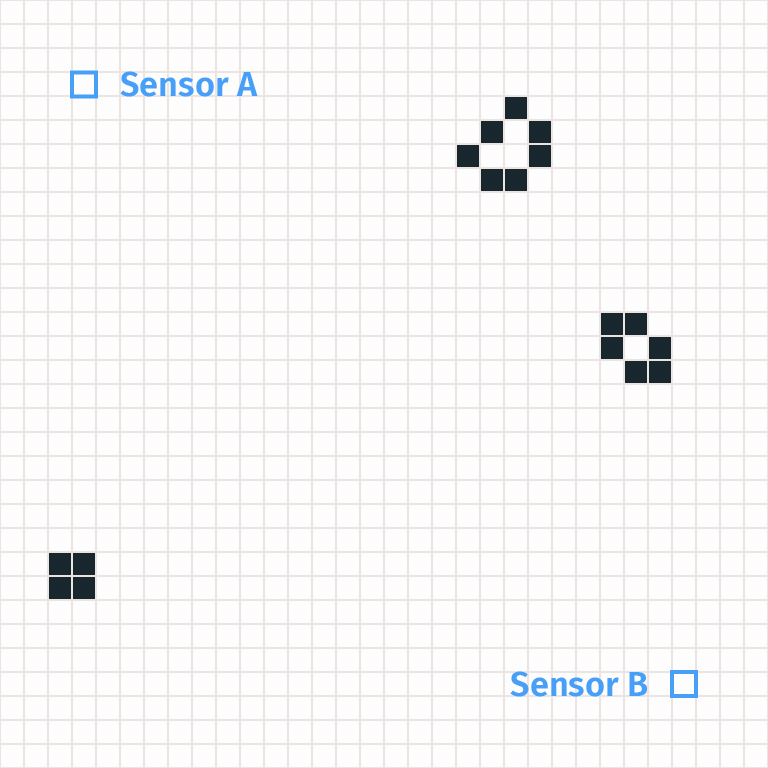
(To be more realistic we could consider physically-implemented sensors, e.g. patterns of cells in the game of life which measure what is happening by interacting with the grid and then recording the information in a computer also built inside the game of life. But that adds a huge amount of complexity without changing any of our analysis, so for now we’ll just talk about these supernatural sensors.)
These scientists don’t know how the game of life works. All they see are the reports of the sensors. They observe that sensor B often fires 100 timesteps after sensor A, which they call an “A-B pattern.” Perhaps sensor A fires on 0.1% of timesteps, and sensor B fires on 0.1% of timesteps, but A-B patterns occur on 0.01% of timesteps instead of the 0.0001% you would have expected if the events were independent.
Scientists hypothesize that A-B patterns occur due to an object traveling between sensor A and sensor B. They call this hypothetical object a “glider,” but they have no idea that a glider consists of a particular pattern of 5 live cells.
To help understand the world, the scientists collect a large training set of sensor readings and train a generative model which can predict those readings, i.e. a function that maps a uniformly random string of bits ε to a sequence of observations for sensor A and sensor B. This generative model is trained to assign a high probability to the sequences in the training set.
The generative model makes good predictions, and in particular it reproduces the surprising frequency of A-B patterns. As a result, the scientists expect that “gliders” must correspond to some latent structure in the model.
Explaining A-B patterns in the generative model
Let’s suppose that the generative model uses the random seed \(\varepsilon\) to fill in a large grid, with 10% of cells alive and 90% dead, simulates the grid for 1000 timesteps, and then outputs the 1000 bits observed by each of the sensors.
To find gliders, we’ll search for a “probabilistic heuristic argument” based on the presumption of independence that A-B patterns are common. We expect that argument to somehow reflect the fact that gliders travel from sensor A to sensor B. We write about formalizing probabilistic heuristic arguments here, but in the context of this post we will make use of only extremely simple arguments.
The most naive heuristic argument is to treat every cell as independent and ask: at each timestep, how likely is it that a cell is alive?
- At timestep 0, each cell has a 10% probability of being alive.
- We can compute the probability that a cell is alive at timestep 1 if each of it and each of its 8 neighbors is alive independently with probability 10% at timestep 0. This results in a 5% probability (this estimate is exactly correct).
- Similarly, we can compute the probability that a cell is alive at timestep 2 if it and each of its 8 neighbors is alive independently with probability 5% at timestep 1. This results in a ~0.75% probability (this estimate is a significant underestimate, because actually the cells are not independent at timestep 1).
- In general, we can inductively compute that at timestep \(n\) a cell has is alive with probability roughly \(\exp(-\exp(n))\) probability of being alive.
This approximation greatly overestimates the decay rate, because after the first timestep the status of adjacent cells are extremely highly correlated. It also underestimates the limiting density of living cells, because once a group of cells is stable they are likely to remain stable indefinitely (this is called “ash”). A more sophisticated heuristic argument could take these spatial and temporal correlations into account, but these errors aren’t important for our purposes and we’ll keep working with this extremely simple argument.
This argument predicts that sensor A and sensor B are completely independent, and so the rate of A-B patterns should be the product of (A frequency) and (B frequency). So we haven’t yet explained the surprisingly high rate of A-B patterns.
One way we can try to improve the argument to explain A-B patterns is by explicitly describing a series of events that can give rise to an A-B pattern:
- With probability about 0.004% per cell, the initialization will happen to contain the 5 cells of a glider. (This is an underestimate, because it neglects the fact that gliders can be created at later timesteps; a more sophisticated argument would include that possibility.)
- If a glider appears, then our naive heuristic argument implies that there is a fairly high probability that all of the cells encountered by the glider will be empty. (This is an overestimate, because we underestimated the limiting density of ash.)
- If that happens on the A-B diagonal, then we can simulate the game of life rules to derive that the glider will pass through sensor A, and then pass through sensor B after 100 timesteps.
So overall we conclude that A-B patterns should occur at a rate of about 0.004% per timestep. This is a massive increase compared to the naive heuristic argument. It’s still not very good, and it would be easy to improve the estimate with a bit of work, but for the purpose of this post we’ll stick with this incredibly simple argument.
Was that a glider?
Suppose that our scientists are interested in gliders and that they have found this explanation for A-B patterns. They want to use it to define a “glider-detector,” so that they can distinguish A-B patterns that are caused by gliders from A-B patterns caused by coincidence (or different mechanisms).
(Why do they care so much about gliders? I don’t know, it’s an illustrative thought experiment. In reality we’d be applying these ideas to identifying and recognizing safe and happy humans, and distinguishing observations caused by actual safe humans from observations caused by sensor tampering or the AI lying.)
This explanation is simple enough that the scientists could look at it, understand what’s going on, and figure out that a “glider” is a particular pattern of 5 cells. But a lot of work is being done by that slippery word “understand,” and it’s not clear if this approach will generalize to complicated ML systems with trillions of parameters. We’d like a fully-precise and fully-automated way to use this explanation to detect gliders in a new example.
Our explanation pointed to particular parts of the model and said “often X and Y will happen, leading to an A-B pattern” where X = “the 5 cells of a glider will appear” and Y = “nothing will get in the way.”
To test whether this explanation captures a given occurrence of an A-B pattern, we just need to check if X and Y actually happened. If so, we say the pattern is due to a glider. If not, we say it was a coincidence (or something else).
More generally, given an argument for why a behavior often occurs, and a particular example where the behavior occurs, we need to be able to ask “how much is this instance of the behavior captured by that argument?” It’s not obvious if this is possible for general heuristic arguments, and it’s certainly more complex than in this simple special case. We are tentatively optimistic, and we at least think that it can be done for cumulant propagation in particular (the heuristic argument scheme defined in D here). But this may end up being a major additional desideratum for heuristic arguments.
Some subtleties
Handling multiple reasons
We gave a simple heuristic argument that A-B patterns occur at a rate of 0.004%. But a realistic heuristic argument might suggest many different reasons that an A-B pattern can occur. For example, a more sophisticated argument might identify three possibilities:
- With probability 0.004% a glider travels from A to B.
- With probability 0.0001% A and B both fire by coincidence.
- With probability 0.000001% an acorn appears between A and B, doesn’t meet any debris as it expands, and causes an A-B pattern. (Note: this would have a much smaller probability given the real density of ash, and I’m not sure it can actually give rise to an A-B pattern, but it’s an illustrative possibility that’s more straightforward than the actual next item on this list.)
Now if the scientists look at a concrete example of an A-B pattern and ask if this explanation captures the example, they will get a huge number of false positives. How do they pick out the actual gliders from the other terms?
One simple thing they can do is be more specific about what observations the glider creates. Gliders cause most A-B patterns, but they cause an even larger fraction of the A-B correlation. But “A and B both fire by coincidence” doesn’t contribute to that correlation at all. Beyond that, the scientists probably had other observations that led them to hypothesize an object traveling from A to B — for example they may have noticed that A-B patterns are more likely when there are fewer live cells in the area of A and B — and they can search for explanations of these additional observations.
However, even after trying to point to gliders in particular as specifically as they can, the scientists probably can’t rule everything else out. If nothing else, it’s possible to create a machine that is trying to convince the scientists that a glider is present. Such machines are possible in the game of life (at least if we use embedded sensors), and they do explain some (vanishingly tiny!) part of the correlation between sensor A and sensor B.
So let’s assume that after specifying gliders as precisely as we can, we still have multiple explanations: perhaps gliders explain 99.99% of the A-B correlation, and acorns explain the remaining 0.01%. Of course these aren’t labeled conveniently as “gliders” and “acorns,” it’s just a big series of deductions about a generative model.
Our approach is for scientists to pick out gliders as the primary source of the A-B correlation on the training distribution. We’ll imagine they set some threshold like 99.9% and insist that gliders must explain at least 99.9% of the A-B correlation. There are two ways we can leverage this to get a glider detector rather than a glider-or-acorn detector:
- We can search for the simplest argument that captures most of the effect on the training distribution, and hope that the simplest way to argue for this effect ignores all of the non-central examples like acorns. This was our initial hope (gestured at in the document Eliciting latent knowledge); while we think it works better than other reporter regularization strategies, we don’t think it always works and so aren’t focusing on it.
- We can search for any argument that captures most of the effect on the training distribution without capturing the new example. If we find any such argument, then we conclude that the new example is possibly-not-a-glider. In this case, we find that simply dropping the part of the explanation about acorns still explains 99.99% of the A-B correlation, and so an acorn will always be flagged as possibly-not-a-glider. This is our current approach, discussed in more detail in Mechanistic anomaly detection and ELK.
Recognizing unusual gliders
Consider an example where a glider gun randomly forms and emits a sequence of gliders, each causing an A-B pattern. Intuitively we would say that each A-B pattern is caused by a glider. But the methodology we’ve described so far probably wouldn’t recognize this as an A-B pattern caused by a glider. Instead it would be characterized as an anomaly. That’s an appropriate judgment, but the scientists really wanted a glider detector, not an anomaly detector!
The problem is that our argument for A-B patterns specifies not only the fact that a glider passes from A to B, but also the fact that gliders are formed randomly at initialization. If a glider is formed in an unusual place or via an unusual mechanism, then the argument may end up not applying.
If the scientists had examples where A-B patterns were caused by glider guns, then they could include those and fix the problem by considering only arguments that capture those cases as well. But they may not have any way to get those labels, e.g. because glider guns are only ever produced in worlds involving complex AI systems who could also tamper with sensors directly in a way that fools the human labelers.
Without the ability to create glider guns on their own, how can the scientists point more specifically to the concept of “glider,” without inadvertently pointing to the entire causal process that produces A-B patterns including the events causally upstream of the glider?
One way to point to gliders is to use two sensors to triangulate: gliders are a common cause of sensor A firing and of sensor B firing, and scientists could try to pick out gliders as the “latest” common cause. This potentially gives us a way to point to a particular point on the causal chain to A-B patterns, rather than indiscriminately pointing to the whole thing.
In practice they would also have many other regularities and relationships they could use to pick out gliders. But this simplest example seems to capture the main idea. We’ll try to make this idea precise in the next section.
Rejecting unusual gliders seems like it might be a serious problem — having an anomaly detector could still be useful but would not constitute a solution to ELK. So a lot depends on whether there is some way to actually point to gliders rather than just flagging anything unusual as anomaly.
Can we point to the latest common cause?
We might be able to implement this by searching over explanations that capture (i) the A-B correlation on the training set, (ii) the fact that sensor A fires on the new example, (iii) the fact that sensor B fires on the new example. We say that the A-B correlation is “potentially not due to a glider” if there is any explanation of this form which fails to capture the A-B correlation on the new example.
Our hope is that any argument which captures the A-B patterns on the training set needs to argue that “if a glider passes through A and encounters no debris, then you get an A-B pattern.” And any argument which predicts that sensor B fires on the new example needs to establish that “On the new input a glider passes through A and encounters no debris.” So an argument which does both things would necessarily need to capture the A-B pattern on the new example.
In contrast, if sensors A and B had fired for separate reasons (or because of some other mechanism like an acorn) then we could imagine an argument that separately argues that each of A and B fires without arguing that an A-B pattern occurs.
One obvious subtlety is that we are separately talking about predicting A, predicting B, and predicting the A-B correlation on a single example, and it’s not clear what it even means to talk about the A-B correlation on a single example. We think it is possible to make sense of this in the context of cumulant propagation, but we don’t know how generally that will hold.
Overall we’re not really able to evaluate this proposal concretely given the informal way we’ve talked about heuristic arguments so far, and we’re just not sure if it will work.
Things that are not gliders
If this all works as we’re sketching, we can speculate about which A-B patterns would be described as “due to gliders” vs “not due to gliders:”
- Not a glider: a glider passes through A and a second glider passes through B.
- Not a glider: a glider passes through A and runs into debris, but then a new glider is immediately created nearby traveling towards B.
- Probably not a glider: while traveling from A to B a glider runs into a piece of debris and starts falling apart, but then hits a second piece of debris that allows it to recover. This effect might appear in the initial argument, but it can almost certainly be separated from the “don’t encounter any debris” component of the argument. If so, then it will only count as a glider if the prevalence of this double-debris scenario on the training set is above the threshold the scientists set for “what fraction of the training set behavior is due to gliders.” We wouldn’t expect it to be for a particular random type of crash that allows a glider to survive, unless that kind of crash was very common or else there was a systematic reason that many different kinds such crashes tended to allow gliders to survive without changing their travel time.
- Hopefully a glider: a glider is created by a glider gun or some unusual mechanism. This depends on the speculation from the last two sections.
- Hopefully a glider: a glider passes through A, and makes it to B only because there is some special glider-escorting-machinery clearing out all the debris in front of it. This is similar to the last point and depends on the same speculation, but also depends on details of exactly how we specify gliders. If we identify glider travel as the cause of the exact 100 timestep difference between the A and B sensors firing, it’s more likely that this would count as a glider (since the timestep difference is caused by the same mechanism, even if the successful gliding was not).
Special cases and false positives
Suppose that for an arbitrary event \(X\) (like \(X\)="cell 33004 is on, cell 40092 is off…") we can divide the argument “sometimes gliders appear and travel from A to B” into two sub-arguments:
- “Sometimes \(X\) happens and a glider appears and travels from A to B”
- “Sometimes \(X\) doesn’t happen and a glider appears and travels from A to B”
Such that the first sub-argument captures the A-B pattern on inputs where \(X\) is true and the second captures the A-B pattern inputs where \(X\) is false.
Then for any given new example, we could pick some property \(X\) which is true for the new example but rare on the training distribution. By selecting the sub-argument that assumes \(X\) is false, we can always find an argument explaining the training behavior but not the new example. As a result, we will always conclude that a new input is potentially anomalous.
It is possible to special case proofs in this way: I can prove (\(Y\) is common) by proving (\(X\) is common) and \(X \Rightarrow Y\), even if the proof of \(X \Rightarrow Y\) completely ignores the assumption \(X\).
We could try to rule this out by looking for the simplest argument, as mentioned above. That might be a workable approach, but it’s not the one ARC is currently exploring.
Instead we are hoping to rule this out structurally. There are two ways this could work, both of which seem plausible:
- Suppose that I have an argument that \(X\) is common and that \(X \Rightarrow Y\), but the argument for \(X \Rightarrow Y\) never actually uses the assumption of \(X\). Then we could hope that this argument still “captures” an input where \(X\) is false, because it is still possible to carry out the \(X \Rightarrow Y\) argument without actually using the assumption of \(X\).
- Rather than searching over all arguments that explain the training behavior, to see if any of them fail to explain the new example, we could find a single argument that explains the training behavior and then look for “subsets” of that argument. If we take this approach and start with an argument \(\pi\) for \(Y\) that makes no reference to \(X\), then we could hope that an argument “probably \(X\), and \(X \Rightarrow Y\)” isn’t a subset of \(\pi\).
A related problem: finding strawberries in the real world
Eliezer sometimes talks about the problem of getting a very smart AI to put a strawberry on a plate. If successful, ARC’s approach to ELK should directly address that problem. In particular, it should be possible to evaluate whether a proposed action puts an actual real strawberry on a particular plate. And that solution should work even if the proposed actions are very complex, e.g. if an AI needs to carry out a complicated military campaign to defend a convoy delivering the last surviving strawberry. Moreover, it should work even if actions of similar complexity could replace the strawberry with a convincing fake (or tamper with sensors) in a way that humans would never notice.
(In Eliezer’s most recent discussions of this problem he specifies that the AI should actually make two strawberries that are “identical down to the cellular but not molecular level.” Defining “identical down to the cellular level” using our approach is more complicated and we think less interesting, though still possible; “put an actual real strawberry on a plate” is more important and more similar to the kinds of subproblems we need to solve.)
In our approach, we’d try to point to a strawberry as the cause of a certain strawberry-observation-correlation we’ve noticed: the shape, the red color, the green stem, the seeds, the flavor, and so on. So to evaluate whether an action is predicted to put a strawberry on a plate we’d evaluate whether it’s predicted to lead to all of those observations, and whether it does so based on the normal common cause.
For concreteness, let’s imagine an AI that has a probability distribution over initial states of affairs, together with a detailed physical model for how those states evolve over time. “Strawberry” exists as part of the prior over initial states — to describe the world reasonably you need to know that supermarkets contain objects with the whole correlated set of strawberry-properties. And this gives rise to a number of arguments that explain the strawberry-observation-correlation:
- The physical properties of strawberries are correlated in the prior over initial states. There is a heuristic argument that object properties are often stable under the passage of time, and so the world contains lots of objects with the strawberry-properties. And there is a heuristic argument that strawberry-properties give rise to strawberry-observations (e.g. that light reflecting off of an object containing strawberry pigments will appear red).
- The prior over the world also contains strawberry seeds, with correlated strawberry-genomes. There is a heuristic argument that when those seeds grow they will produce berries with the strawberry-properties, and then we proceed as before to see that such objects will lead to strawberry-observation-correlations. If the model has seen long enough time periods, we’d also need to make arguments about how the grandchildren of strawberries themselves have strawberry-properties, and so forth.
- We’ve assumed a detailed physical model starting from a distribution over initial conditions. But you could also imagine more heuristic models that sometimes treated strawberries as ontologically fundamental even after initialization (rather than treating them as a set of atoms) or whose initial conditions stretched all the way back before the evolution of strawberries. We won’t talk about those cases but the arguments in this section apply just as well to them.
Now we can imagine the same approach, where we say that something “there is a strawberry on the plate” if we make the strawberry-observation and any argument that explains 99.9999% of the strawberry-observation-correlation also captures the strawberry-observation in this case. What would this approach classify as a strawberry vs not a strawberry?
- Not a strawberry: an imitation strawberry constructed in a lab in New Jersey to exactly imitate the appearance and flavor of a strawberry. In this case the strawberry-observations are not due to the physical strawberry-properties. I can explain more than 99.9999% of the strawberry-observation-correlation in the training data without ever talking about the fact that sometimes people try to make objects that look and taste and feel like strawberries. (This is only true if I define my strawberry-observations stringently enough that there are very few fake strawberries that pass all my tests in the “training” dataset I’ve used to define strawberries.)
- Not a strawberry: an atomic replica of a strawberry. Now the strawberry-observations are due to the physical strawberry-properties, but the correlation between all of those strawberry-properties is not due to the normal reason. We can imagine someone copying the atoms to reflect parts of the strawberry but not others, and the correlation is induced by facts about the strawberry-copying machine rather than the correlations in the prior. That is, I can explain 99.9999% of the co-occurence of strawberry-properties without ever arguing that people sometimes make atomic replicas of strawberries.
- Not a strawberry: a copy of a strawberry made by sequencing a strawberry, synthesizing an identical genome, growing the resulting plant, and picking its berries. The strawberry-properties are now due to the same genes unfolding through the same biological processes, but now the gene-correlation is occurring for an unusual reason: in order to explain it I need to make a heuristic argument about the sequencing and synthesis process, and I an explain 99.9999% of the training set behavior without making such arguments.
- Strawberry: a strawberry picked by a robot from a field. Now the correlations are due to the usual fact, namely that my prior over states involves a bunch of strawberries with correlated strawberry-properties that are preserved unless something bad happens. We can’t explain 99.9999% of the correlation on the training set without making heuristic arguments about how strawberries can be transported while preserving the relevant physical strawberry-properties. But note: that if robots picking strawberries is unprecedented, this depends on the same complexities discussed above where we need to distinguish explanation for the correlation from explanation for the individual properties arising in this case (because the heuristic argument for strawberry-observations depends on strawberries actually getting in front of the camera, and so you need to make a heuristic arguments about humans picking and delivering strawberries without damaging them which may not apply to robots picking and delivering strawberries).
- Not a strawberry: a strawberry picked by a robot from a field, smashed in transit, and then carefully reconstructed to look as good as new. Now the strawberry-observations are still produced by the physical strawberry-properties, but those properties are preserved by the reconstruction process rather than by the usual heuristic argument about strawberries preserving their properties unless they are disturbed. But note: this depends on exactly how we define strawberry and what we take to be a strawberry-observation, ideally the reconstructed strawberry counts as a strawberry iff the smashed up strawberry would have counted and that’s up to us.
It’s interesting to me that an atomic replica of a strawberry would clearly not be considered a strawberry. Initially I thought this seemed like a bug, but now I’m pretty convinced it’s exactly the right behavior. Similarly, if I ask my AI to move me from point A to point B, it will not consider it acceptable to kill me and instantly replace me with a perfect copy (even if from its enlightened perspective the atoms I’m made of are constantly changing and have no fixed identity anyway).
In general I’ve adopted a pretty different perspective on which abstractions we want to point to within our AI, and I no longer think of “a particular configuration of atoms that behaves like a strawberry” as a plausible candidate. Instead we want to find the thing inside the model that actually gives rise to the strawberry-correlations, whether that’s ontologically fundamental strawberries in the prior over initial states, or the correlation between different strawberries’ properties that emerges from their shared evolutionary history. None of those are preserved by making a perfect atomic copy.
Comment via LessWrong, Alignment Forum.